Many languages feature a random number generator library for help with tasks like rolling a die or flipping a coin. Why, you may ask, is this necessary when humans are perfectly capable of randomly coming up with values?
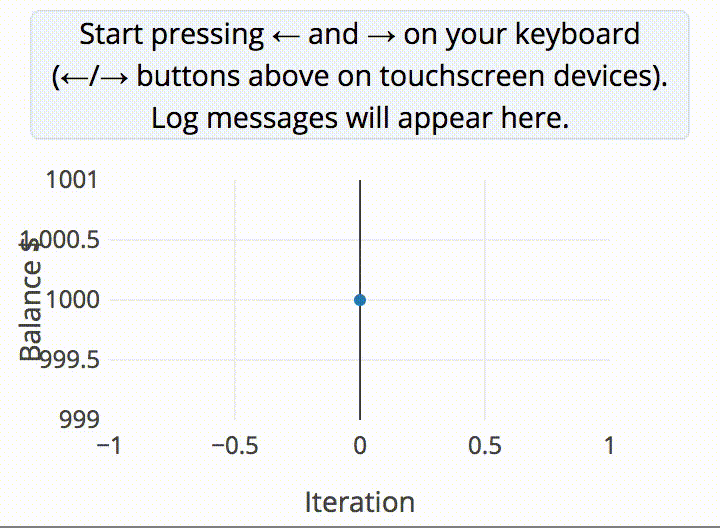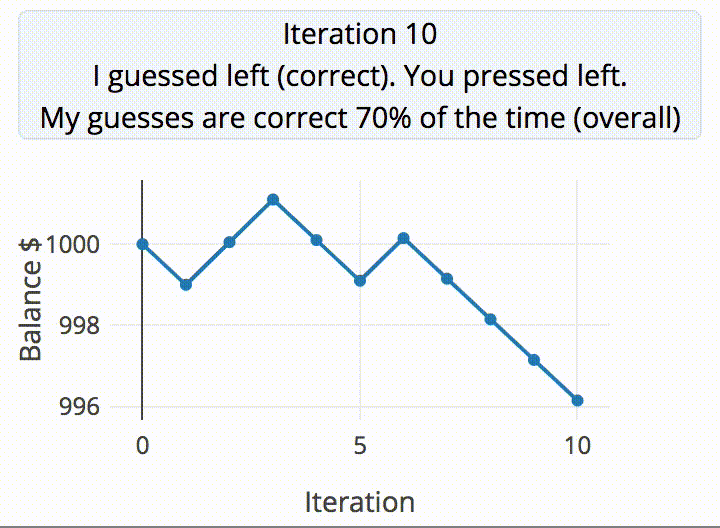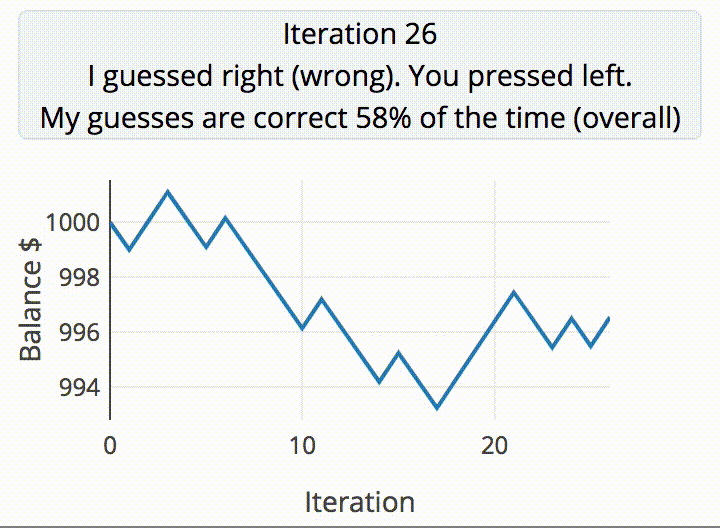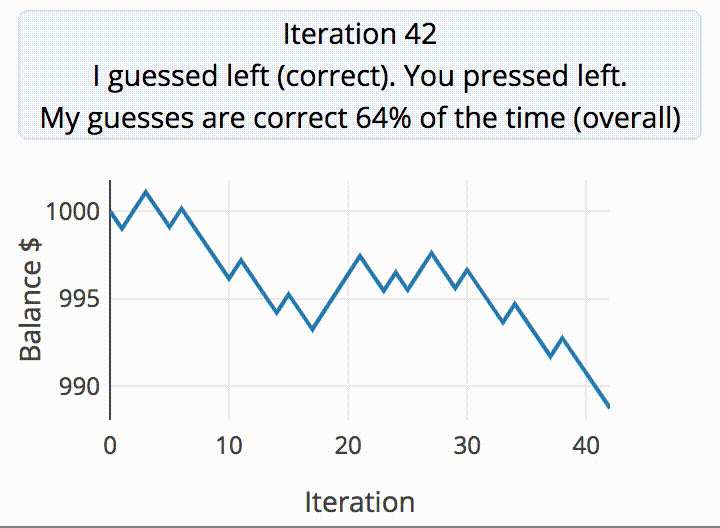
[ex-punctis] was curious about the same quandary and decided to code up an experiment to test the true randomness of human. A script guesses the user’s next input from two choices, keeping a tally in the JavaScript backend that holds on to the past five choices. If the script guesses correctly, they take $1 from the user. Otherwise, the user earns $1.05.
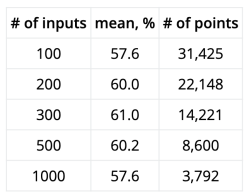
The data from gathered from running the script with 200 pseudo-random inputs 100,000 times resulted in a distribution of correct guess approximately normal (µ=50% and σ=3.5%). The probability of the script correctly guessing the user’s input is >57% from calculating µ+2σ. The result? Humans aren’t so good at being random after all.
It’s almost intuitive why this happens. Finger presses tend to repeat certain patterns. The script already has a database of all possible combinations of five presses, with a counter for each combination. Every time a key is pressed, the latest five presses is updated and the counter increases for whichever combination of five presses this falls under. Based on this data, the script is able to make a prediction about the user’s next press.
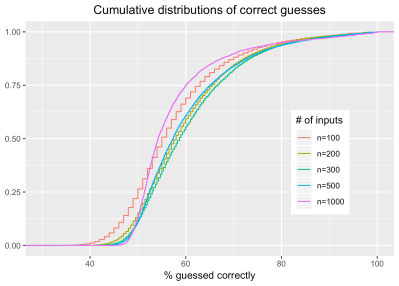
In a follow-up statistic analysis, [ex-punctis] notes that with more key presses, the accuracy of the script tended to increase, with the exception of 1000+ key presses. The latter was thought to be due to the use of a psuedo random number generator to achieve such high levels of engagement with the script.
Some additional tests were done to see if holding shorter or longer sequences in memory would account for more accurate predictions. While shorter sequences should theoretically work, the risk of players keeping a tally of their own presses made it more likely for the longer sequences to reduce bias.
There’s a lot of literature on behavioral models and framing effects for similar games if you’re interested in implementing your own experiments and tricking your friends into giving you some cash.













However if you knew that it was working on your last 5 presses, you only need to work around this to figure out how to make money ;)
Yes, humans are terrible at random, but we’re good at making money ;D
ok. now try that with a full fledged keyboard in stead of left right…
Sure, but usually random generators don’t have to produce a binary output… beside exactly guessing the opposite of a sequence of the last 5 presses is absolutely not the definition of random.
A better experiment would have been challenging the computer with numbers from 0 to 9, or with the whole keyboard; I do think that in that case a grater randomity of the user’s action would have been found.
In David Ahl’s Basic Comp[uter Games 2 book, there was a game called “Flip” which did exactly this, with storing 4 previous results from a coin flip. So this is not a new idea.
I remember some text about vegetables which ended up with a sentence: quickly think of some number – it’s six right? And almost always it was six.
I also once read about some guy doing some job in field who said: I always carry pencil (pen smears if paper gets wet) and a dice (guessing random number is not working).
What I want to say is that everybody with a little knowledge knows that people suck at being random – it’s nothing new. I would like to see this algorithm against some numbers from some more or less popular random numbers generators (specially the one for small platforms with little resources) or flipping coin (maybe also flipping coin by several different person?).
Once I had an idea to make some “dice roller”+”coin flipper” that would be running every few seconds and returning results online for people who need random numbers for some testing but this appears also to be not random enough.
I thought this would be about the “randomness” of pseudo-random generators, which of course have a sequence that always repeats. Though if the hardware or software has enough length, it’s close to random for many purposes.
The Apple II generated “random” numbers by waiting for a keypress. I never saw any analysus of how that worked out.
Various BASICs had a pseudo-random generator, but allowed for a seed that meant the sequence didn’t have to be the same each time.
Linux has a driver that does provide random numbers, but requires hardware to generate the numbers, and I don’t have the hardware.
Start with a random source of white noise, like a reverse biased diode, and you can get random numbers after converting to digital.
Michael
I seem to be able to hold it at 69% (giggity). I’m like, so random and qwerky.
I hacked the code, plugged in a random number generator, and now I’m a millionaire!
I’m afraid Claude Shannon beat you to this, he made a similar machine using relays that used the same strategy to “read the mind” of the human, as it always scored better. In this paper “A Mind-Reading (?) Machine – Bell Laboratories Memorandum, March 18, 1953”. Shame it’s locked up behind the IEEE paywall.
I’m wondering ….suppose you got an average human to write down say 10,000 letters in his best effort at randomness. The result would presumably not be very random, but clever folk would be able to produce a measurement of how predictable it was compared to true random. Now suppose you put our human’s 10,000 letters through a (currently) low tech machine encryption such as Enigma and so came up with 10,000 letters of Enigma ciphertext. That too would be not very random. But would it be only a teensy bit closer to random than the origial human plain text. Or would it be a lot closer to random ? In other words would applying a low tech shuffling mechanism to human generated random text improve the lack of predictability a lot, or a little ?