Introduction
In this blog post, we will take a look at how we will be tracking request in Node.js.
Motivation (WHY?)
If we look at postal services like Fedex, UPS etc., they will provide us with a tracking number using which we can track the package status from their website.

It is such an important functionality, using which each customer can track their package status at any time.
Similarly, in a Service Oriented Architecture, we will have a plethora of services talking to one another using HTTP protocol following REST or SOAP architecture. When a client initiates a Web request using browser, request traverses through all these distributed services to fulfill a particular request. Diagrammatically it can be shown as below:
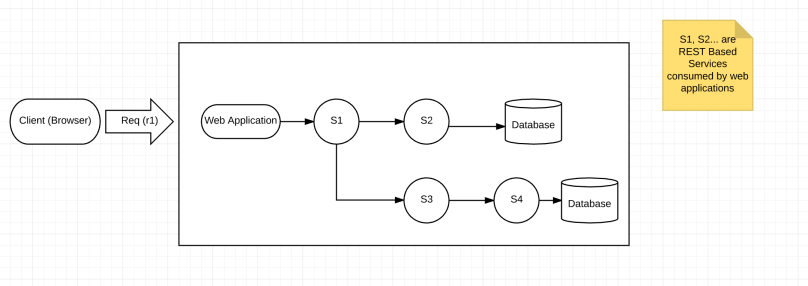
Similar to how we track packages, we need to track what happened to a particular request r1 initiated by a client. Typically when the web application receives the request, it will generate a unique identifier called correlationId and track any information in its application logs by tagging this correlationId. Also when the web application makes any service calls it will pass along this correlationId as a Request HEADER key/value pair. Subsequently, those services will use the same correlationId while they log their information. This unique identifier is thus carry forward to all the services which are involved in fulfilling a single request r1.
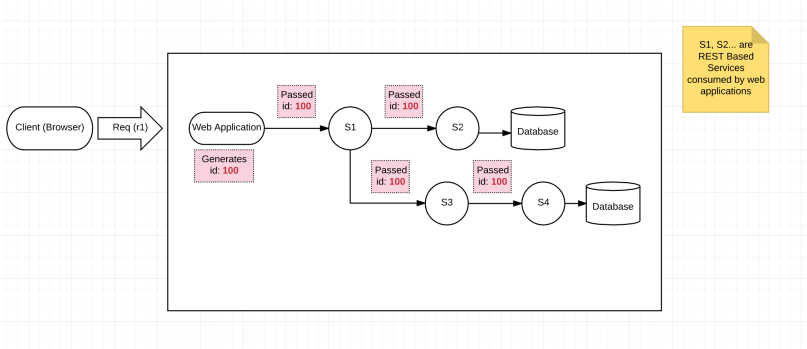
Passing along the same correlationId for a given request is very important for a variety of reasons:
- When a given request fails, we can exactly know the reason why it failed and which service caused the failure.
- We can tell how long a given request took and can measure exactly how long each services in turn took to process a given request
- If we have all information logged for a given request
r1we can write aggregate queries to figure out:- How many request was served by a given endpoint in a min/hr/day range?
- How many 2xx/4xx/5xx occurred for a given endpoint in a min/hr/day range?
- What is the average/95th percentile response time taken for a given api to respond for a given request
r1? - etc.,
It is very clear that tracking a given request r1 using correlationId in Service Oriented Architecture is critical to understand how our systems are behaving.
Implementation (HOW?)
Solution in JAVA
We will take a simple example of providing a stock price web application which retrieves stock price based on the company name. The flow is as follows:
- Client (Browser) makes a call by passing company name. for eg:
Walmart - Web application receives company name and then calls
StockServiceto retrieve the stock ticker symbol.(Walmart => WMT) - Web application gets the stock price by passing stock ticker symbol to
StockServiceand renders the webpage with the result.(WMT => price)
In the above example, we will focus how logging is implemented in the web application layer, since the process is the same across other layers in the stack.
UML diagram can be shown as follows:
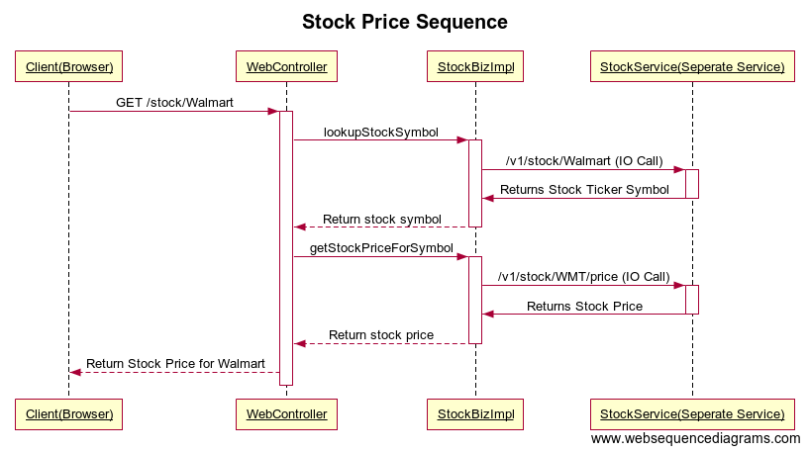
In this example, web application is written in Java and it includes WebController and StockBizImpl in the above diagram. We will not worry about the implementation of Stock Service(Separate Service).
To satisfy our logging requirements in JAVA web application we need to do:
- Generate a unique
correlationIdwhich is tagged along in every log we generate in the web application - Pass this unique
correlationIdwhen we make 2 service calls. One to retrieve stock ticker symbol and the other to retrieve stock price.
Solution 1:
A quick solution would be to create a class called Context which will hold the generated correlationId. This object will be created by WebController and then each function which needs to either log or make a service call, will accept a new function parameter called context. For eg: public void process(String value, Context ctx, ...). This solution works but as we can see, the function signature gets tainted with Context ctx everywhere in the code and also we need to keep passing Context ctx wherever it’s required which is not elegant.
Solution 2:
How do we solve it in a way, that any portion of the code which is handling a given request somehow automatically gets the Context object without having to explicitly pass it as a parameter? THREADLOCAL to the rescue.
Java provides a ThreadLocal object using which you can set/get/remove thread scoped variables. 3 key functions:
- set(T value) – It is generic over type T
- get()
- remove()
Assuming we are developing a J2EE web application running within Tomcat, blocked thread pool implementation., Tomcat will have a worker thread pool of size n and each thread will be allocated to handle a given request and once completed the thread goes back to the thread pool. Typically, we will register a filter which will create a Context object and set in ThreadLocal. This object can be accessed in the entire request lifecycle within the same thread and when the control comes back to filter, it will remove the context from ThreadLocal since threads will be reused by Tomcat as they go back to the thread pool. Solution is a Filter acting as a Decorator and ThreadLocal acting as the container of the object within the given thread of execution.
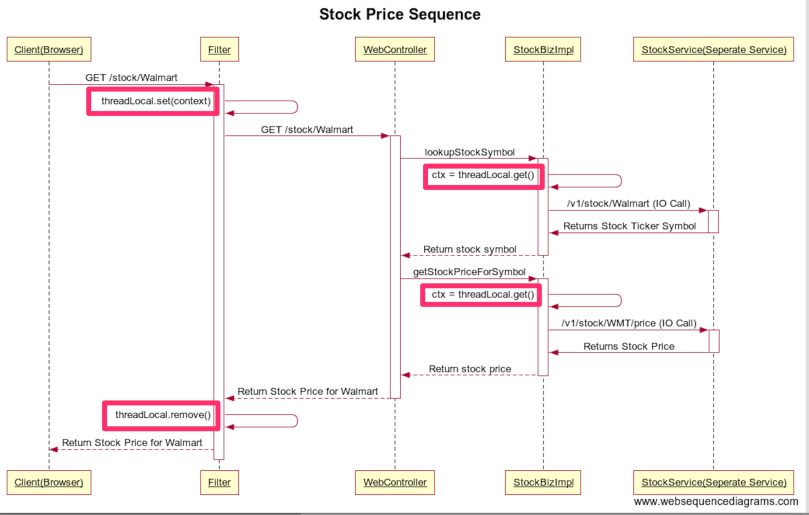
Solution in Node.js
We will take a simple example of generating a correlationId in one event loop and subsequently retrieve the previously set correlationId value in another event loop which is part of the same callback chain.
Solution 1:
Similar to Java solution 1, we can append the Context to request object under request.app.ctx with a new value for correlationId. In the code wherever we need the correlationId from the Context object in the entire callback chain for a given request, we will simply use closure and close over the request object. Like in Java solution 1, it is not elegant as we have to close over the request object to access request.app.ctx wherever we need the ctx object in the request lifecycle.
Solution 2:
If we look at the above Java solution, the 3 key methods set(T value), get() and remove() do not have to pass in thread id to do CRUD on thread local objects. It is completely abstracted away by the implementation of ThreadLocal which makes the solution elegant. If we are looking at the signatures of set, get and remove from the lens of a functional programmer, we can clearly see that they are side-effecting operations. To me, both OOP and FP offer elegant solutions for various kinds of problems. In this use case, even though they are side-effecting operations, it does not clutter the code to pass the Context object all around and provides a very simple and elegant solution.
As we all know, Node.js is single threaded following Continuation-passing style. How do we solve this problem in this environment?
We will look at a simple Node.js code to understand what we are trying to achieve:
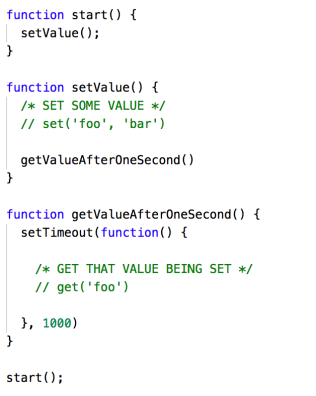
What we would like to achieve is set an object with key:value pair and register some callback events using setTimeout for example in one event loop and then we should be able to retrieve the previous set value by passing the key in the subsequent event loop when the callback actually gets fired.
We have taken the cue from the Java implementation. In the above Node.js implementation, we have come up with setters and getters using set(key, value) and get(key)respectively and the object values stored using set should be automatically made available to the entire callback chain in a transparent manner and should be able to be retrieved using get. Decorator and ThreadLocal solution in Java becomes Monkey Patching and Use of Closures in Javascript.
What is MonkeyPatching ?
A monkey patch is a way for a program to extend or modify supporting system software locally (affecting only the running instance of the program).
A simple example of monkey patching setTimeout and the callback we pass to it can be shown as follows:
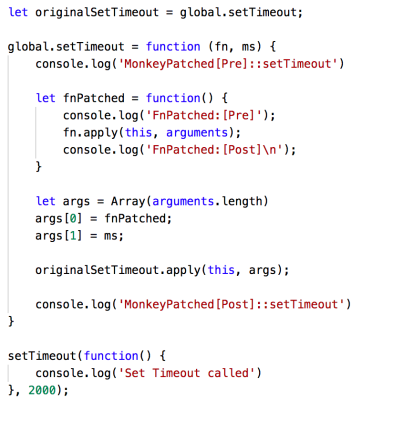
As we can see above, both setTimeout and callback that we pass to it is being monkey patched. Since the client has already tied their code with setTimeout / callback the only way to augment the behavior of setTimeout / callback is by monkey patching.
Solution using Monkey patching and Closures

namespace.js

As we can see above, setTimeout and callback passed to it is monkey patched. In the patched setTimeout function, we are closing over the active context value at that point in time t. In the patched callback function, we are setting the closed active value what was at time t while entering, run the actual callback function, resetting the active to an empty object while exiting. We start everything off by running namespace.run(fn) where run function creates a brand new active object, sets the active object while entering, executes fn (in this case start) and then resets the active value while exiting.
Continuation Local Storage
An open sourced module called Continuation Local Storage solves the above problem for Node.js in a powerful and elegant way. You can go over the source code link to understand more about the module.
General code flow for passing around context in a generic way using Continuation Local Storage can be shown as below: (Took the below example from Continuation Local Storage )
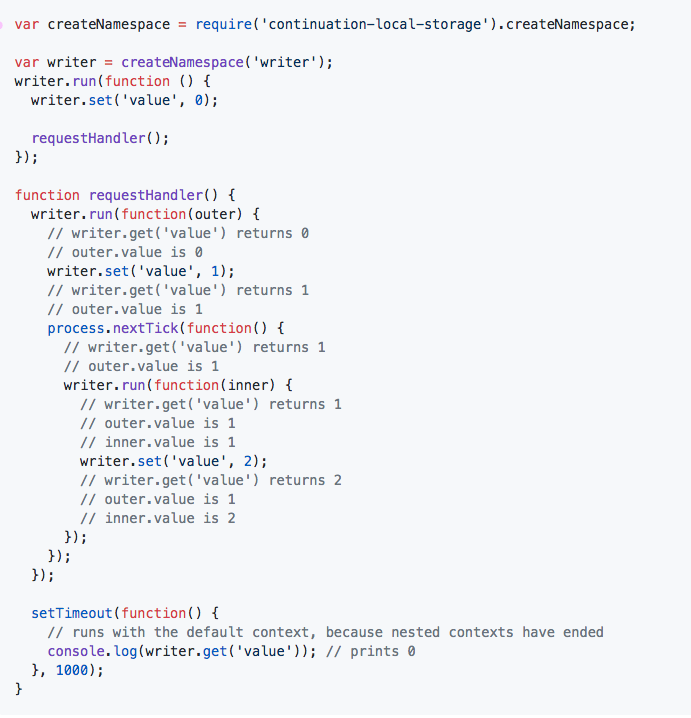
Continuation Local Storage is a very powerful and complex module. Since in Node.js, IO are non-blocking operations, this effectively means Continuation Local Storage module needs to apply monkey patching to a variety of functions. The module at a very high level does the following:
- Handling variations of logic for different node versions
- Monkey patch functions from the below objects:
net.Server.prototypehttp.Agent.prototypechildProcess.ChildProcess.prototypechildProcessprocessglobaldnsfszlibcryptoPromise- etc…
- Support
CLSforEventEmitter - Handling
errorscenarios - Provides
namespaceusing which we can start a new execution usingrun, and for read and write operation, we can usegetandsetrespectively.
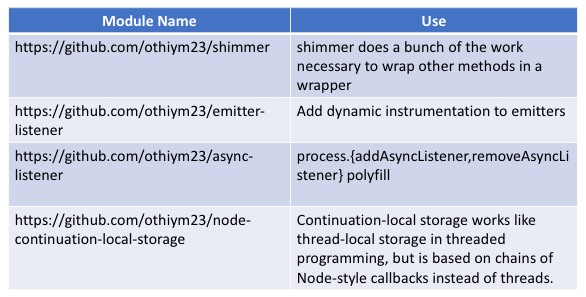
Modules
Summary
Tracking a request in Node.js using correlationId is not very easy compared to how it can be implemented in a language like Java. Node.js asynchronous IO makes it very hard as the code structure becomes completely callback-driven. Continuation Local Storage is one of the most powerful and complex modules which solves this problem in a very elegant way for Node js. Even if we are not planning to use this module in a real world application, just by looking at the source code implementation we can learn so much about the complexity involved in solving such a simple use case in Node js and the author’s brilliance in the way of its implementation.

[…] Link: https://vmayakumar.wordpress.com/2017/11/07/tracking-request-in-node-js/ […]
LikeLike
[…] Introduction In this blog post, we will take a look at how we will be tracking request in Node.js. Motivation (WHY?) If we look at postal services like Fedex, UPS etc., they will provide us with a … Read more […]
LikeLike
[…] Source link […]
LikeLike