
I came across a good discussion about complexity from one of the industry’s network probe vendors. Applying Metcalfe’s law, the blog reinforced what we’re all acutely aware of; the number of connections – not simply between servers, but between multiple processes on servers – inside today’s data centers is exploding. Here, I’ve crudely recreated a few diagrams often used to illustrate this.
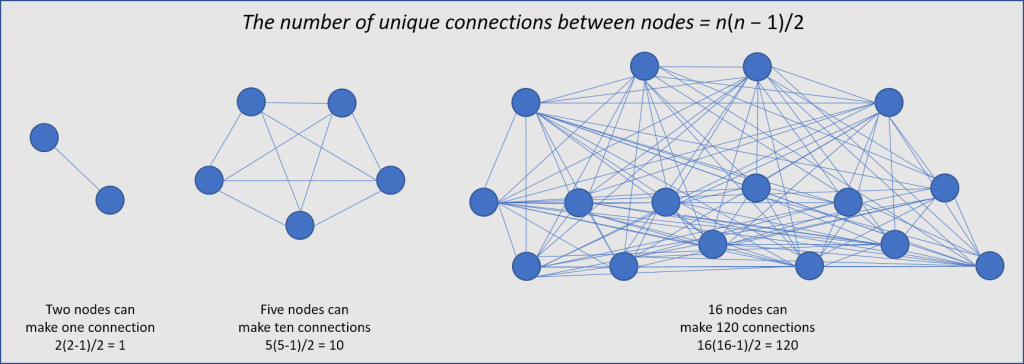
This rapidly increasing complexity drove corresponding data center network architectural shifts, from hierarchical layouts (where north-south traffic dominated) to flattened and micro-segmented leaf/spine layouts that can more effectively support this server-to-server or east-west traffic.
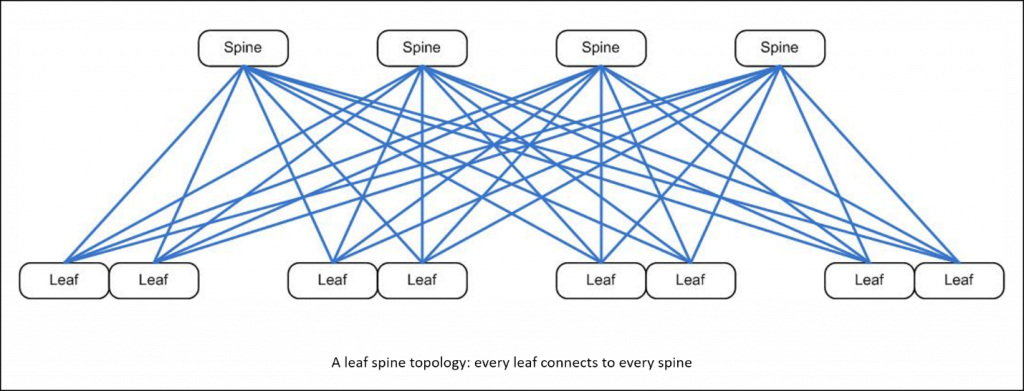
It’s no coincidence that the flattened network architecture shown here resembles the most complex of the Metcalfe diagrams I drew; direct switched network connections between communicating hosts are inherently more efficient than multi-hop hierarchies.
At the same time, increases in virtualization density frequently introduced scenarios where inter-VM traffic never had to hit the (physical) network.
Existential angst
Slowly but surely, these shifts resulted in the loss of traditional traffic aggregation points that had become an enabling foundation of a network probe’s value. They presented an existential problem, and probe vendors found themselves in a battle for territorial survival inside the modern data center.
Unspoken panic can be a great motivator, and vendors entered the fray from multiple flanks; after all, if all you have is a probe, then every problem must be visible on the network. Early skirmishes saw sometimes convoluted network configurations intended to route communications on to physical links or up to artificial aggregation points. Some took the approach of installing virtual probes on each host. More recent and sophisticated battles look to deploy virtual network port mirroring and virtual taps. Even the unbiased treaty negotiators – analysts and services companies – have touted fundamental revisions to data center architectures to include “visibility planes” through distributed network packet brokers (NPBs).
Battles continue to rage on in the trenches. But even through the thick fog of war, the outcome is taking clear shape. Data center architectures are designed to provide agile application services. Providing access to network packets takes a much lower priority, to some degree in anticipation of alternate monitoring approaches.
Tough questions
How many probes are you willing to deploy in your data center? How many taps – real and virtual – would you need for full Metcalfe-like visibility? What kind of supporting network will you need to route this traffic to your probes? How will these stopgap solutions respond to the ever-increasing dynamics of data center traffic, of connections, of the services themselves? And the most important question: to what end? To monitor application performance?
It seems reasonable, then, to conclude that network probes are not going to maintain their value for intra-data center monitoring. Take the current trajectory to its logical conclusion, where every host, every VM, every container sits on its own segment with a direct virtual path to dependent peers. Should every node have its own virtual probe? And if not – how will you measure the quality of node-to-node communication in the virtualized environment?

Straight answers
Now replace the words “virtual probe” in the above paragraph with “software agent.” Suddenly, the problem of data collection isn’t so daunting; the agents do all the work, offering access not only to host network interface statistics, but also to process-level network communications – including access to network packets themselves– along with compelling host and app performance data. The challenge shifts quickly to the high-value opportunity of data analysis. And that’s where automation, full-stack visibility and AI come to play.

Is the network probe dead?
Not by a long shot.
If we consider the data center probe in terms of its traditional form-factor, it’s clear it doesn’t fit well in today’s dynamic and cloud-like data center architectures. But the value of network analysis endures; in fact, some argue this may gain importance as containerization, micro-segmentation, and dynamic provisioning gain firmer footing, relying more heavily on Metcalfe-like network meshes. Inside the modern data center, these insights will be derived from software agents rather than physical – or even virtual – network probes.
In fact, attempting to fulfill an outsized APM-like role may have contributed to the probe’s struggle for relevance. As Digital Performance Management (DPM) and in-depth transaction tracing become the exclusive realm of agents and APIs, there exists a natural opportunity to use these same agents to also deliver fundamental network insights. This leaves NPM – along with user visibility – for the probe, leading to this rhetorical question: Is probe-sourced wire data really the best way to understand the performance of a data center’s core network? Or can agents do the job?
Of course packet-based TCP flow analysis will also remain important, offering the most objective source of network performance insights; these insights, however, have always been more valuable on the WAN. And that is where we’ll see traditional network probes settle – rather comfortably, actually – into the role they were designed to play, shifting to the place they have always belonged: the edge of the data center, where they can continue to deliver clear value.
Monitoring at the edge of the data center
What makes the data center edge so well-suited for a network probe?
- First and foremost, the WAN – traditional, hybrid, optimized, software-defined – is where network characteristics and TCP flow control behaviors are most likely to have an impact on application performance and availability.
- Second, today’s WANs incorporate many devices and appliances that influence performance and availability through factors that go beyond such traditional NPM micmetrics as bandwidth, latency, loss, and routing. These appliances include WAN optimization controllers (WOCs), application delivery controllers (ADCs), load balancers, firewalls, even thin client solutions. They not only control traffic flows through TCP manipulation, they also often perform server-like functions, independently delivering some application content directly to users. Yet they’re still considered part of the network.
- Third, the number of WAN access points to your data center – and therefore the number of probe points – is relatively small, avoiding the Metcalfe matrix problem.
- Fourth, these access points often already have wire data access solutions in place for IDS, important to security teams; these network packet broker (NPB) solutions can easily prune and share raw packet streams with a network monitoring probe.
- Last – but not least – end-user experience is arguably the most important metric by which to measure service delivery quality. The probe’s vantage point at the data center edge provides the best perspective to deliver this value, as it can see all user interactions with your data center apps.
Equipping the network probe with the intelligence to understand application-specific transactions and automatically analyze performance degradation makes it an invaluable triage point for BizDevOps teams responsible for application delivery and performance. User experience remains the common actionable metric important to all three groups.
It’s worth noting that, just a few short years ago, some pundits were announcing the death of the network probe; the inability to receive packets in PaaS and IaaS clouds presumably foretold a rapid demise. But the speed at which this problem has been solved by the leading NPB vendors (such as Ixia and Gigamon) proves the resilience and value of the probe at the data center’s edge. We’ve started to see this trend, working with our customers to achieve monitoring continuity as they move their complete application infrastructures from on-premises to IaaS clouds.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum