
This article is the fourth part of our Azure services explained series. Part 1 explores Azure Service Fabric, in part 2 we focused on Azure Functions, while part 3 discusses Azure IoT Hub. Today let’s have a look at Azure Cosmos DB and what the “world’s first globally distributed database” can do.
If you are running your business in the e-commerce, gaming, or IoT sphere, Azure Cosmos DB is your best friend. Usually, applications in these three areas are built to serve millions of users around the globe, to handle massive amounts of reads and writes, and manage user-generated content and data. Since the birth of cloud computing and PaaS solutions, implementing a globally distributed and scalable database isn’t such a big thing. But Microsoft took this to the next level by creating a multi-model database service that transparently scales and replicates your data wherever your users are. And that’s quite a big thing.
Welcome to Azure Cosmos DB
Azure Cosmos DB is Microsoft’s globally distributed database service that allows you to manage your data even if you keep them in datacenters scattered throughout the world. It is a NoSQL database (doesn’t rely on any schemas), and it can support multiple data models using one backend (it can be used for document, key value, relational, and graph models).
As Microsoft puts it, “Azure Cosmos DB makes global distribution turnkey”. This means, you can add Azure locations to your database anywhere across the world, at any time, with a single click, and Cosmos DB will seamlessly replicate your data and make it highly available. It allows you to scale throughput and storage, elastically and globally. You only pay for the throughput and storage you need, anywhere in the world and anytime.
But it all started messy
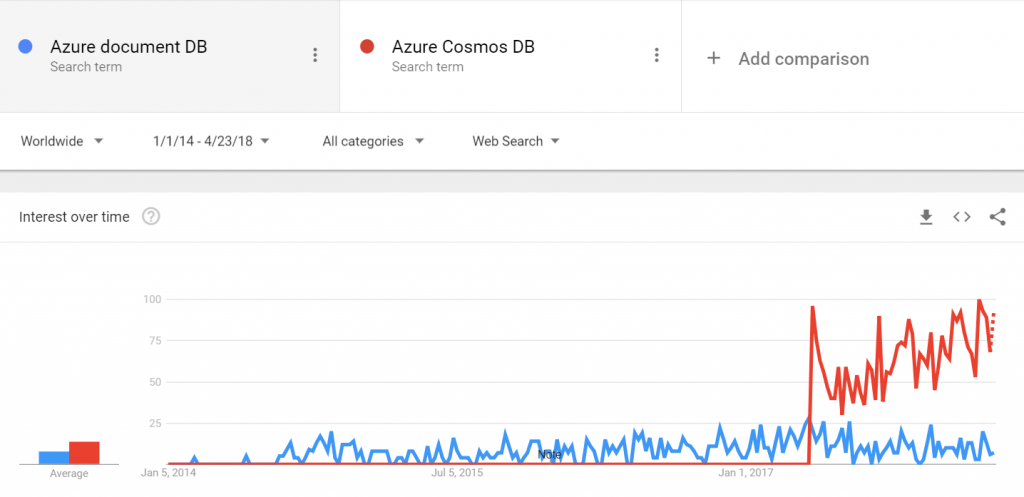
The first thought of Cosmos DB can be traced back to 2010. The story goes that several teams inside Microsoft kept bumping into the same problems of data at scale. Teams like the Xbox or the Office 365 team handle large, geographically dispersed user bases, moving terabytes of data around the planet, while making bits of them simultaneously available with very high uptime and low latency for millions of users. This process caused trouble repeatedly until someone said: Let’s build up a team for this and try to solve it ourselves. So, “Project Florence” started in 2010. Being successful, in 2015 they decided to make some elements of the project public—the database service that we knew as Document DB.
Document DB had a two-year career, as such. At Build 2017, Microsoft announced Azure Cosmos DB, a service that subsumed Document DB. Those who were using Document DB automatically became Azure Cosmos DB users—also a testimony to the power of a managed service.
What problem does Cosmos DB solve?
Obviously, not too many enterprises have to scale to 100 trillion transactions per day spanning multiple regions like the Office 365 team, or some of the leading e-commerce companies. But, as cloud-based applications increasingly scale, reach global users, and power AI experiences, every enterprise needs to start thinking about data at planet scale. To make their users happy, enterprises must ensure the lowest possible latency, the highest possible availability, and predictable throughput. Their database systems need to be scalable and globally distributed, meaning that all resources are partitioned horizontally in every region of the world, as well as replicated across different geographical areas. This is what Cosmos DB does well.
One database to rule them all
Most commercially distributed databases fall into two categories:
- Those that don’t offer well-defined consistency choices at all
- Those that offer two extreme programmability choices (strong vs. eventual consistency)
While the former expects users to make difficult tradeoffs between consistency, availability, latency, and throughput, the latter creates pressure to choose one of the two extremes. Cosmos DB’s most notable feature is that it provides five well-defined, intuitive consistency choices (strong, bounded-stateless, session, consistent prefix, and eventual consistency). So, users can select the one that fits their app the best.
A short list of some of Cosmos DB’s other capabilities:
- It natively supports a multitude of popular query APIs, so you can access your data using the API of your choice: SQL, Gremlin, JavaScript, Azure Table Storage, and MongoDB.
- It automatically indexes data, so you can perform amazingly fast queries without having to deal with complexities of schema and index management in a globally distributed setup.
- It allows you to elastically scale across any number of geographical regions.
- It guarantees comprehensive SLAs for latency, throughput, consistency and high availability.
- It’s a managed service ready to use, powered by Azure, providing tools that developers need to scale both global distribution patterns and computational resources within planet-scale apps.
Databases are easy to start, but difficult to master
You can deploy the most powerful database in the world, but it won’t be of any use if you can’t get answers to the most important questions. Typically, you would ask questions like:
- What’s the average time spent across all web transactions occurring within a selected time frame on the server-side? (Response time)
- How many requests per minute go through my application? (Throughput)
- What’s the percentage of errors over a particular analysis time frame for my application? (Error rate)
- Which database statement takes the longest to execute?
- How will I know if my database is giving my customers a hard time?
You must monitor that!
Thanks to the MongoDB API, Cosmos DB databases can be used as the data store for apps written for MongoDB. This means, you can easily build and run MongoDB apps with Cosmos DB, while continuing to use familiar skills and tools for MongoDB. It also means that you can monitor Cosmos DB via Dynatrace OneAgent support for MongoDB.
Let me show you how easy it is
If you’re using Dynatrace, and a Cosmos DB database happens to land in your environment, Dynatrace will automatically detect it, and name it in a way that makes sense to your DevOps staff. Also, Dynatrace provides a real-time view of your entire stack so you can see all the connections between your database and other services, including any 3rd party services.
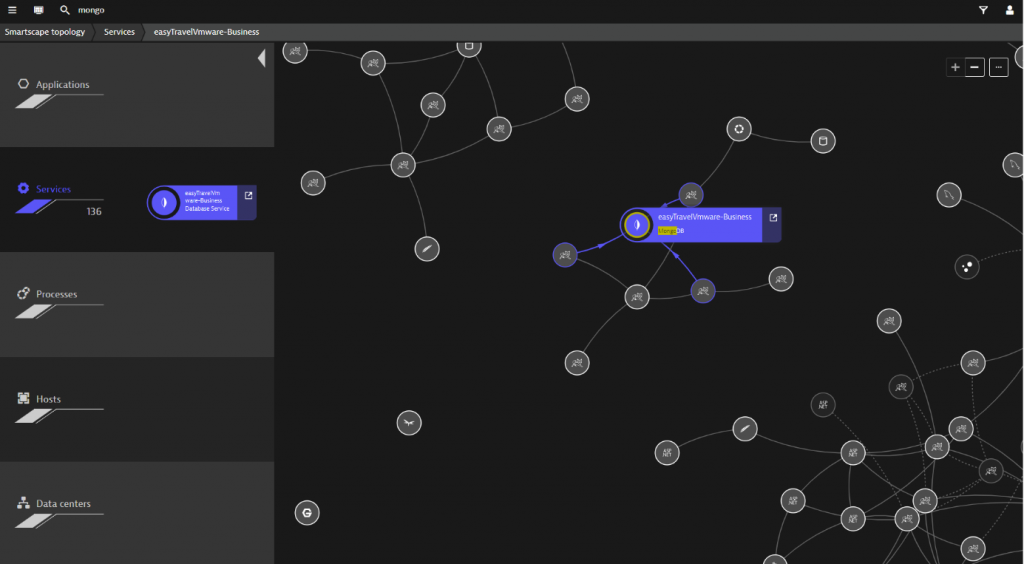
At the same time, Dynatrace begins to collect and deliver Cosmos DB / Mongo DB metrics. These include the numbers of calls and response times—all visualized according to aggregation, commands, read-, and write operations.
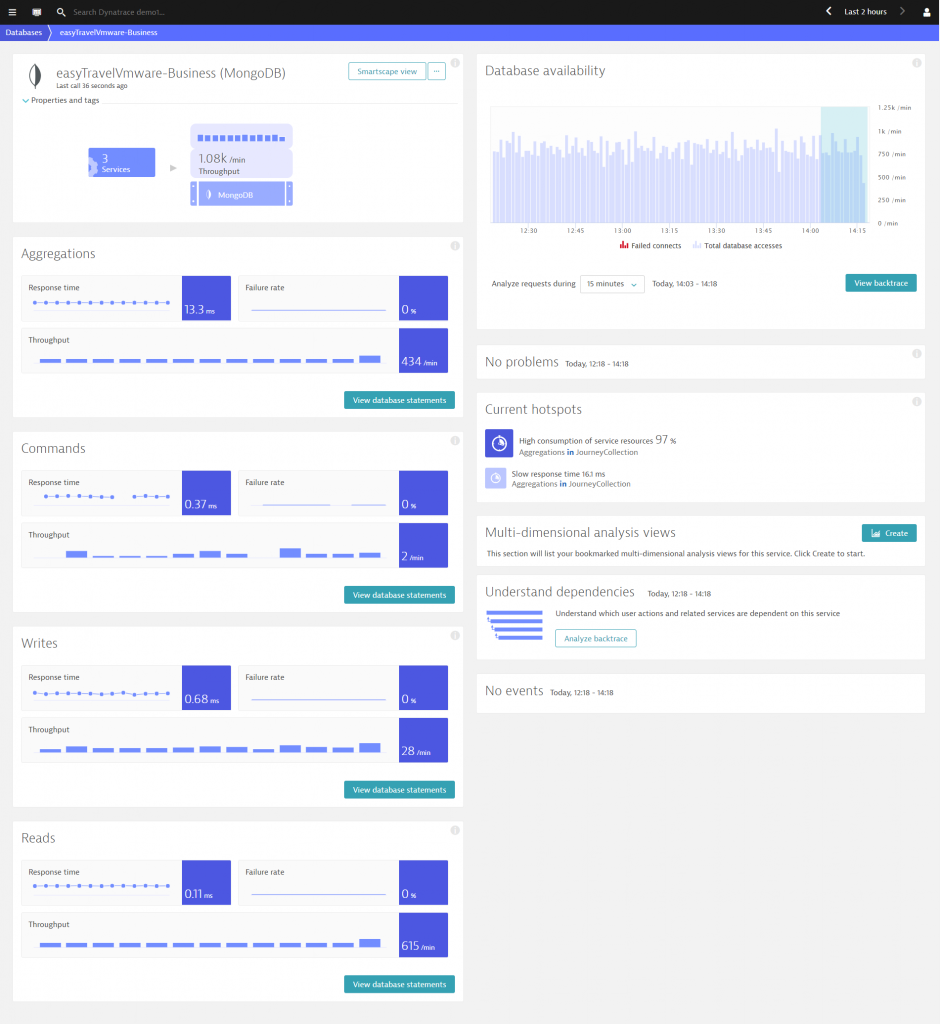
Wondering which Cosmos DB / MongoDB statement is responsible for a detected response time or load spike on your database? Dynatrace tells you exactly which database statements are executed in your environment.
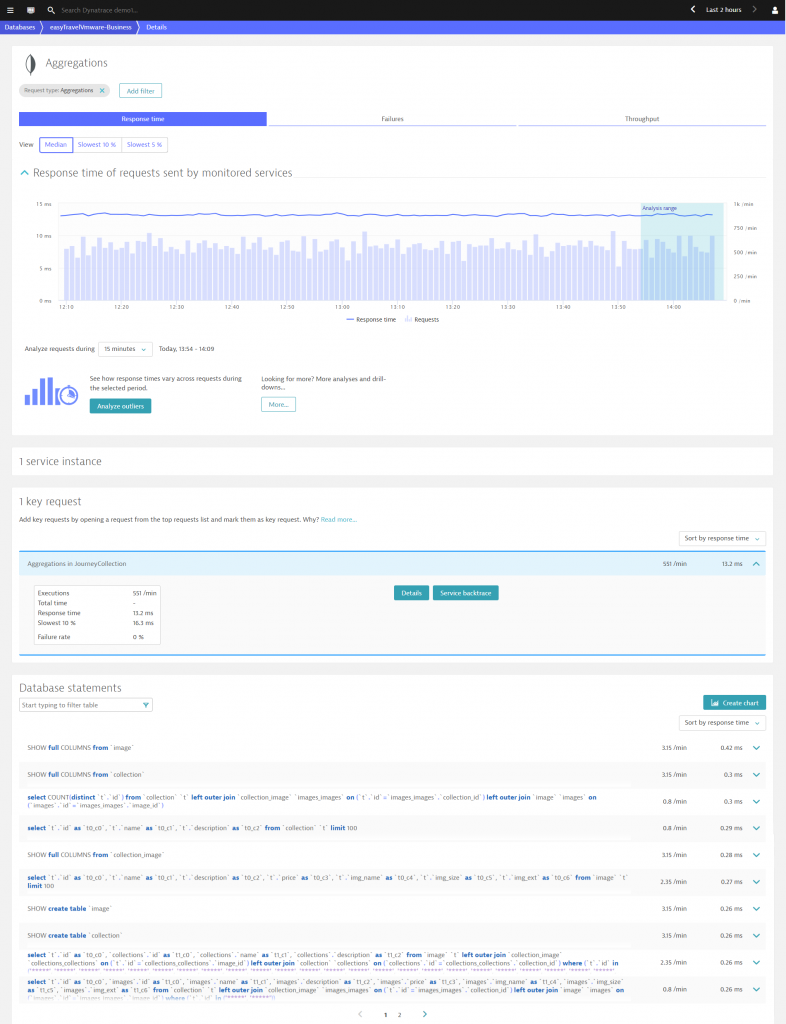
And, to take this to the next level: Dynatrace also detects exactly which database statement is the root cause of each degradation. Looking at the example below you can see that the MongoDB database has been identified as the root cause.
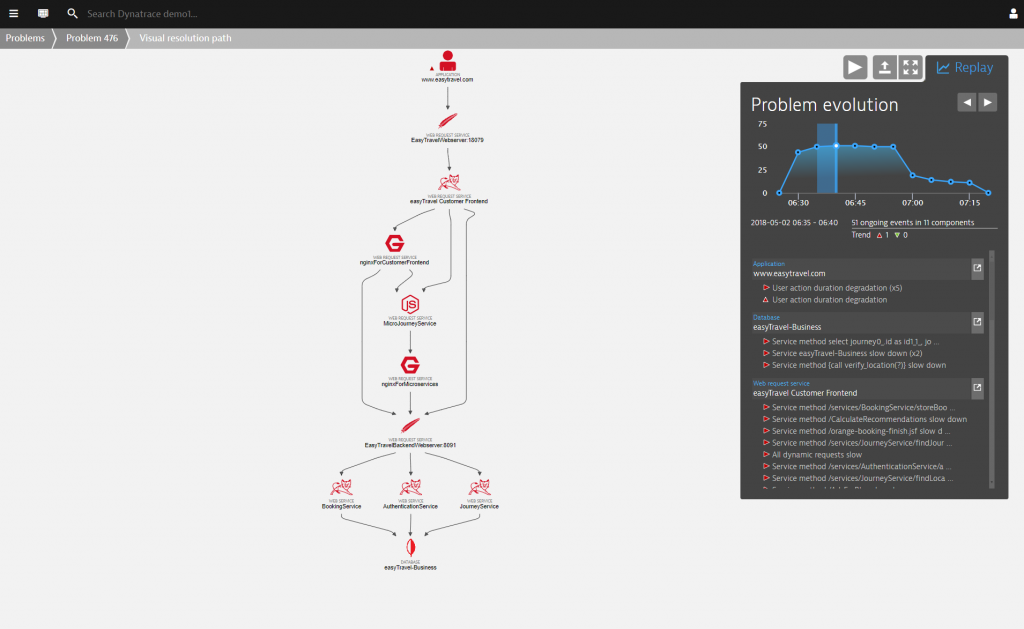
What’s really impressive is the fact that this type of root cause analysis is available for far more than direct calls—Dynatrace artificial intelligence understands causation throughout your entire IT environment, all events and transactions end-to-end and therefore knows the full impact that database problems have on your system.
A complete description of how Dynatrace database monitoring works is out of the scope of this article, but you can read all about Dynatrace database-service monitoring in Dynatrace Help.
Wrapping up
More and more enterprises realize that there’s not much value in running databases—the value is in the products and services they build using them. Flexibility, agility, and cost savings are the three main reasons why cloud databases are key to your business success. Obviously, this only plays out if the availability and the SLAs around these services are enterprise grade. This is why Azure SQL, Amazon RDS, and Google Cloud SQL have become forces to be reckoned with.
With Azure Cosmos DB, however, Microsoft sets the bar high. If you have customers around the world, you’ll value Cosmos DB’s ability to replicate data globally for performance and resiliency. Also, if you run a microservices architecture, and each service has different workload and performance characteristics, being able to vary the consistency levels without moving to a different technology provides numerous benefits.
But obviously, this is only true if you have the right monitoring solution in place. Look for a monitoring solution built for the cloud—like Dynatrace. With Dynatrace, you’ll know the behavior of your database in production within about five minutes following installation.
Do you use any cloud-based databases? What’s your take on running databases in the cloud vs. on-premises? Share your story in the comments section below. I’m looking forward to learning from your experiences.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum